
Building an Enterprise Application in Flutter


Building an enterprise-scale application in Flutter, as in any other framework, requires a specific approach toward organizing the team and the code they create. After system architecture, organization and communication are pivotal to secure yourself a smooth path toward the milestones on the roadmap for large-scale projects.
In this comprehensive article written by Mateusz Wojtczak, you will learn:
- How do we ensure code ownership in the team?
- What is the proper structure of the code?
- How to manage separate packages?
- What can be done to facilitate communication in Flutter enterprise projects?
- How to handle the navigation in large-scale Flutter apps?
- How to implement localization in the Flutter enterprise app development?
- Is there a way to avoid mismatches between the backend and frontend contracts?
- How to tame the legacy in a large-scale Flutter app?
- How to implement the Design System in an enterprise Flutter app?


What is a large-scale application?
Why is building an enterprise app so much different than for a startup or small scale-up? When we’re talking about large projects, we mean a project spread across different teams, companies, and business domains because development is only a small part of the whole. In small projects, we often know every developer who’s working with us. There’s even a huge possibility that a backend developer that serves us some API sits next to us the whole time. It’s much easier not to worry about some issues when we don’t encounter them. In large-scale apps, we are rarely in a situation where, while building a powerful contract-based asynchronous communication with our backend, we can just go get some coffee with the backend team and discuss everything.
So, in large projects, we just want to help ourselves - to deal with multiple obstacles that we cannot directly resolve - obstacles that are not only related to code. Let’s see how we can wrap our heads around this level of complexity in terms of code and, most of all, in communication.
In this study, we would like to share our thoughts and experiences from our two-year-long journey of developing a very large banking mobile application using Flutter working with 30 Flutter Developers spread across 15 teams. Check our Credit Agricole case study to learn more.
Code ownership
Let’s talk about code ownership. In a small project done by a single team, there isn’t much to discuss (or is it?). The team wrote it; they own it and are responsible for it. Although they might internally split the responsibility further, it doesn’t change the external perception - a team owns the code. The reality might be slightly different, but it will boil down to this variation. If the team does not own the code, it will deteriorate quite quickly. So let’s pretend that this happens every time.
However, what if we are talking about a not-so-small project? In this case, there were, at the highest point, 30+ mobile app developers split into 12 business teams (also known as squads). We might say that this is just a simple extrapolation - each team owns the code they create. That would be true. Mostly. The problem arises when we realize that the teams work on a single app and single codebase. A. Single. Codebase. So, by another extension, if every team creates the code in the same codebase, then is every team responsible for basically everything?
In that case, no one will be responsible for anything. There might be places where some people will feel responsible for themselves, but that will be an exception. If you find a bug, nobody will be willing to fix it because that will always be someone else’s problem. If you need another feature, you will need to write it yourself because no one cares.
Team ownership works because the team members feel responsible for what they create. There is a natural limit to this - if too many people will “feel” responsible for a piece of work, no one will really feel responsible because always someone else will feel more adequate.
We need to follow the limit and put boundaries exactly where they are. In a project of this size, these will not come out naturally. We need to put them and abide by the rules explicitly. If we do this right from the start, it will not feel artificial and won’t be questioned.
After all, the rule is natural. And everyone feels like it. Everyone feels responsible for their work, but we need not allow a situation when too many people feel that for the same piece of work. That is the problem, and that’s why we need to overcome it by introducing explicit code ownership.
Let’s put some ground rules on how we define code ownership in a Flutter project of this size.
First and foremost, every line of code is owned by a team. Not a single person, a team. Even if the team consists of a single developer, it is still the team's responsibility to maintain it. Developers are rarely self-governing, and there is always someone else (“business people”) that prioritizes the work.
That’s why a single person should never be responsible for a piece of code. If that happens, then doing anything with it will require going through so many managers with different priorities that it will never, ever change. Teams are part of the structure at a level that gives them enough power to correctly prioritize the work around the code and pay for it by “wasting” hours of work. A single person cannot do that.
This leads us to the fact that, even if a team has a single dev and they switch teams (or leave), the responsibility stays with the team. There rarely is a situation where a team gets dismissed or the whole staff of a team leaves. That’s why there will always be a person that owns that piece of code (even if from a business perspective).
And by responsibility, we mean that the code is maintained by the team. If a bug is found in a code owned by the team, their responsibility is to reserve time for a fix and do it. They also need to ensure that the code adheres to the always-changing coding standards. It doesn't, however, mean that only they are allowed to add new code there. If there is a need, someone else outside of the team can edit the code - but that does not change the one responsible; it’s still the team.
And although I am rather pragmatic when it comes to all the rules, meaning “there can always be exceptions,” this is the one that I think should be followed with religious devotion. Otherwise, there will be problems.
So, we know that we need to preserve ownership, but how should we define who owns which part of the code? When a single team develops a whole application (be it a small mobile app or a microservice on the backend), the rule is simple: they own everything they create. There will be some shared code in terms of internal libraries, but these will be created and maintained by a different team, and we probably won’t see the code at all - we will just consume it. In a big Flutter application that is developed at a rapid pace, that’s not that simple. Effectively everyone works on a single codebase, sometimes with not-so-clean business responsibilities. Of course, we could introduce very clear boundaries and physically separate the teams, but that would introduce so much friction and so much grunt work for the one responsible for putting it all together that the development would grind to a halt. We need to find a different way.
And, to be honest, the answer is not that far away - let’s split the project into packages, the same way we would do when splitting physically, but keep everything in the same repository and reference (& compose) using just normal path references. This will make the boundaries clean, but the walls won’t be so high - you can always look into other teams' codes without any fuss because they are right there, a click away. You also compile everything at once, provided that you enforce that on CI (and you should!); everything will work more or less at all times. You will also, just by a random chance, test other people’s code.
As with everything, this is not a silver bullet. This approach has problems that need to be overcome. For once, because the walls are not that high, there is the possibility that someone will modify the code behind the owners' back. This might be a problem when your team does not want to adhere to rules but is primarily an organizational one - and I would say that if that happens, you have other, more critical problems.
There are real things that are problematic and will bite you from day one.
In every project, there is always a “common” folder for things used by everyone and a place where the local packages are bootstrapped and combined to create the final application binary.
We really don’t want these kinds of packages because they don’t have clear ownership - everyone writes code there (directly or indirectly), but no one feels responsible for it. We also can’t ditch them completely because we need to have some shared ground; otherwise, we would re-implement the same thing over and over again (which will happen, but with common - at a much smaller scale). We also need an “app” package - the one that brings everything together. This one is even more important than the first one - we can’t replicate it. We are required to have a single entry point to the app. And everyone needs to contribute to the app. :)
We cannot make an exception for these two. Not abiding by this rule will be far more disastrous than following it. This means that we need to find a way.
We found out that the approach that works is not to find some team that naturally fits to be the owner of this kind of code. What works is to create an “artificial” technical team. The team should be responsible for all the things that no one else wants.
Don’t mistake it for a team of exiles, they have a much more important role.
And although it might seem like a bad idea. They don’t bring clear business value. They seem like a team that no one needs - no business product owner, they don’t create end-user features, and you can’t easily plan their work in sprints.
However, their work is vital. You can’t possibly allow 30+ people to work on a single codebase and expect that they will come up with a coherent, maintainable architecture. That they will never stomp on each other’s toes. That they will spontaneously combine everything into a single application. That won’t “just” happen. There might be natural-born leaders that will do this work because they will feel like they are the ones that should do it, but leaving that to chance will make the process longer and more painful.
Every project of this size requires a team of “architects,” someone that overlooks the development, someone that puts the basics in place and puts the ground rules of development. The team is responsible for the code that no one needs, and they are responsible for making sure that everything works together. They put in the ground rules and ensure they are followed. They design how to (technically) communicate and try to satisfy every developer need that is not directly related to the business but needs to be done.
Keeping up with every developer’s needs can be exhausting. And that is not the only responsibility of a technical team. As I said, they are responsible for the overall architecture and keeping everything in proper order. Although it might not seem as much, that is a lot of work. Every small technical bug, every small optimization, and every small feature that is required to make the app work and be maintainable will, in the end, be their responsibility. The technical team, although not at all times, will have plenty of work.
Because at the end of the day, someone has to be responsible. And if no one wants to be responsible, the technical team will be.
Feature-based project structure
Starting the project often starts with us thinking about how we can structure this one better than the previous one. There are multiple propositions of structuring code; we have a lot of architectural patterns that enforce or promote some. There are two main approaches - we call them horizontal and vertical structures. You may have heard about layering your code. It’s a common thing that people propose to divide code into layers that handle different abstractions.
The layers often go from the end user (UI layer) through some view & application logic until they reach pure data - that means some domain logic or data contracts. That’s what we call a horizontal approach.

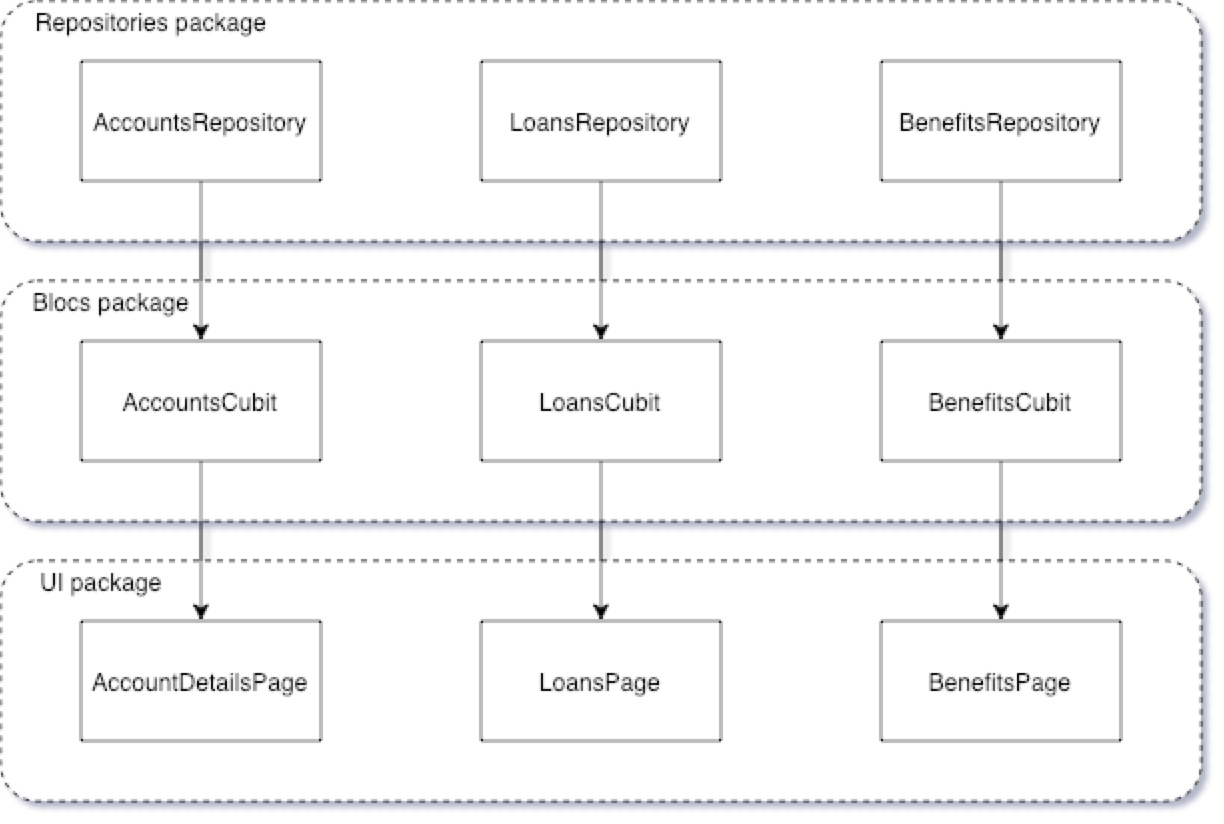
As we can see in the diagram, in this example, we have a UI layer with some Flutter widgets, an application logic layer with some Blocs/Cubits, and a data layer with repositories that represent our data sources. While it may not seem so bad, it can actually corrupt our project in the long run. Let’s see what that architecture really means.
Why do we structure the code? To organize it better. Why organizing? To communicate better. That’s really something that we can build our code structure on. As it was said in previous chapters, we really need code ownership. So, let’s try to answer this question: Who owns the repository package? Who owns the widgets package?
Well, everyone and no one, of course. We could bring an iconic software aphorism in here - Conway’s Law. It states that:
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization's communication structure. — Melvin E. Conway
So, what does it mean for us? It means that no matter how we structure the code, it would still end up shaped similarly to the organization. That means we would like to project our organization’s communication structure onto our code so that we don’t have to divide our code artificially; we just do it as we do with the rest of our work. In that case, let’s ask ourselves: how do we communicate? Well, is there a “Repository Daily Meeting”? Is there a “Widgets Daily Meeting”? Not at all.
The team is most likely divided into business squads that have their responsibilities according to some business domains. In that way, there are also people in squads that are crucial to proceed but are not even next to software development. Ok, so we have our “Loans Squad Daily Meeting.” We can talk about business requirements, and as developers, we can extract business knowledge from other people and process it so that we know how to build the software around that.
In this domain-driven workflow, let’s come back to code structure. Let’s try to project our communication model onto that:

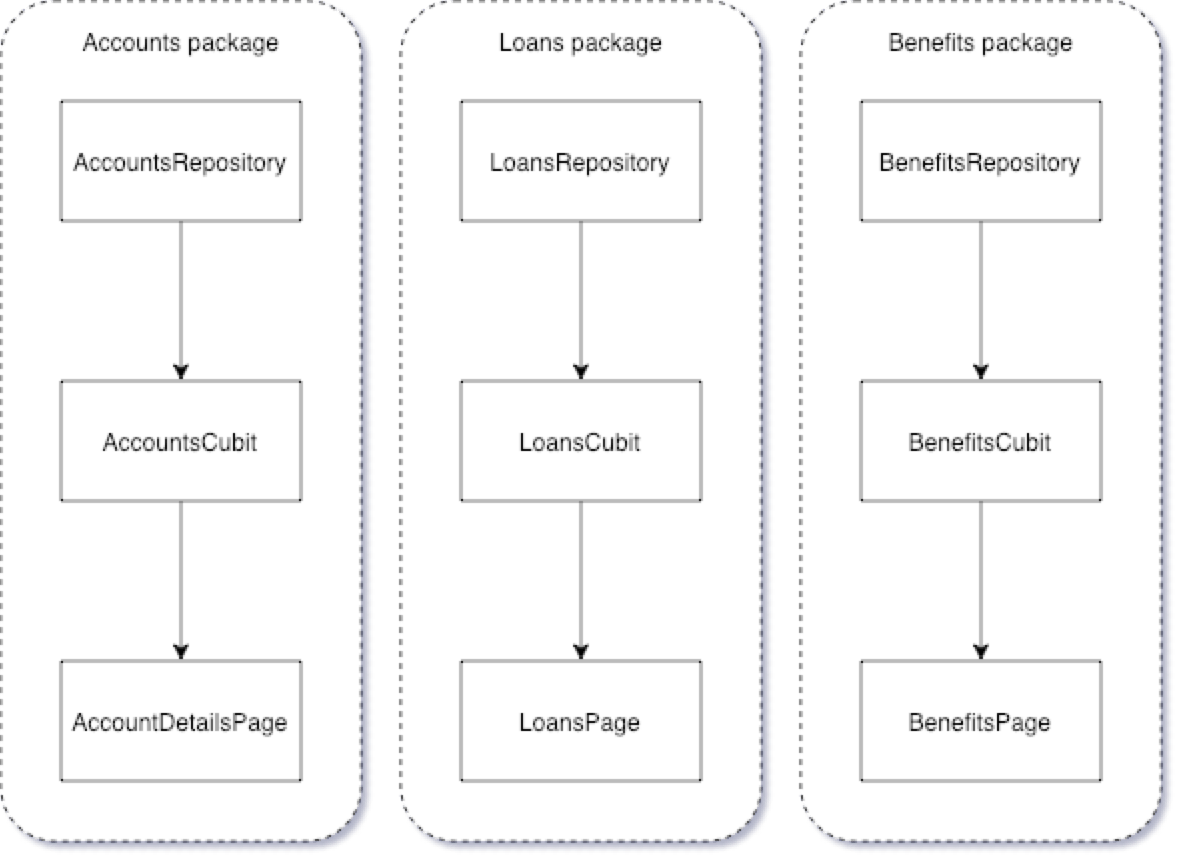
Now we can see that if the same developers work on anything related to loans, then they don’t have to work outside their packages. This way, we also minimize code conflicts between squads. Our daily work will revolve around those packages that are directly owned by our squad. That’s what we call a vertical approach, allowing us to maintain a large project code structure.
Also, this example shows a 1:1 relation between squads and packages. Actually, it’s a bit of a different rule. As it goes with previous code ownership assumptions, we allow multiple packages per squad. It’s perfectly normal that some larger business domains are still strictly related to the squad, but Devs need another package for that.
For example, “Onboarding Squad” can have their onboarding customer journey but also a KYC (Know Your Customer) module that seems to be separate and organized in a separate package. The important thing is to remember that one squad can own many packages, but every package should have only one owner.
However, this doesn’t exhaust the subject of code structure. What about the actual code inside the package? It’s also essential to have some guidelines here. That’s because you want your code structure to be predictable. When one developer swaps squads with another, you don’t want them to spend weeks studying the code before anything really happens.
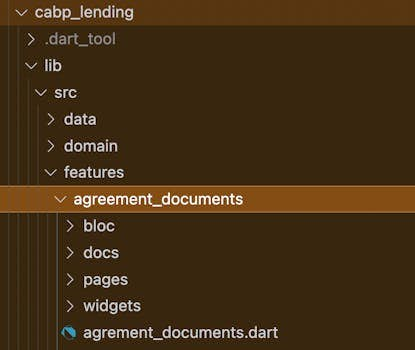
How can we organize it inside the package? Let’s use the same assumptions as with package layering. Let’s try to make a vertical approach inside packages. To do that, we need to define the core unit of our work: in our example, it’s a feature. In agile development, a developer does a user story enabling users to do something related to the business. If we want to let users see their loan agreement documents, then we have to do everything from UI to data sources because otherwise, the feature doesn’t make sense. So, we can define our features inside a package, and inside every feature, we can split our work into blocs, widgets, pages, data classes, etc. What happens inside a feature directory stays there. For other devs, it’s a black box as long as they don’t need to go in there.

Running tasks in mono repo
The next crucial thing in large projects is simplicity and consistency in daily tasks. What we mean by that is we don’t want to have trouble restoring dependencies in our package. A developer would want a simple way for running tests just in their packages, running formatting, etc. To run all these things in a multi-package environment, we need a task runner like Make or “*insert your favorite language*ake.” It would be really convenient if we had a task runner that is somehow aware of Dart/Flutter packages and is adjusted to the ecosystem we work in.
Fortunately, we found that there already are things for that. One that we have selected is Melos. It’s officially described as “A tool for managing Dart projects with multiple packages.”. That’s pretty much exactly what we need looking at the description.

Melos provides a couple of scripts itself, such as:
- Automatic versioning & changelog generation.
- Automated publishing of packages to pub.dev.
- Local package linking and installation.
- Executing simultaneous commands across packages.
- Listing of local packages & their dependencies.
It helps maintain many popular packages like FlutterFire (Firebase libraries for Flutter), Flame (game engine), or Flutter Community Plus plugins. However, the most important thing is that you can run any shell script in each package directory, and you can filter what packages it should consider.
It’s really helpful because you can define such scripts and filters once, write some simple docs (although melos.yaml file is already pretty convenient to read) and help new developers on your team be quickly onboarded in the environment. Having a task runner also simplifies building a CI/CD pipeline because some tasks are already defined there.
Last but not least, you can use concurrency for your scripts. But beware of that because your Flutter scripts may fail to run in parallel. In some cases, there will be locks so that even if you start it concurrently, the tasks would still have to wait for each other. Also, Melos command output can end up messy when a lot of packages are being considered since it doesn’t maintain the order - simply speaking, the output is mangled from all the executions.
Still, it’s a great tool, and you probably should use it, especially when working with large Flutter projects.
Cross-squad communication
The physical split into (local) packages does not solve all the problems. And, unfortunately, they amplify others. Life is not simple. Although you might have a “clean cut” when it comes to team responsibilities, you must assume that there will be a point when someone will need someone else.
With twelve squads and a banking app, some features depend on data from other squads, and some invalidate data in others.
You can’t possibly have an app that has 12 completely separate features. Take, for example, the accounts in a banking app - it is the most essential feature to see a list of accounts that you own. Every feature depends on it this way or another. For example, when you see a transactions list (another basic feature), you must see it in the context of an account. On the other hand, when a payment is made, it changes the account balance, another property of the account.
As you can see, there always will be dependencies between teams. What is worse, the dependencies will not be unidirectional. There might be cases where two teams need to communicate with each other in both directions. One example is: you need some data (must be synchronous), then you do something and expect someone else to update the aforementioned data (might be asynchronous).
But that is just one example, and arguably simpler (to maintain, not to develop) because you can easily invert the control by, e.g. using events, resulting in what is effectively uni-directional dependence. But there are cases where you need access in both directions. I personally worked on a squad that provided basic authorization functionality, which was used by arguably every squad. On the other hand, when displaying some auth-related configurations, I needed the information from accounts. This couldn’t be made asynchronous - everything needs to be provided now. And we have a cyclic dependency that, although solvable without too much fuss, is another thing to maintain.
And because of the plethora of options, we need to put some constraints there so that we can do everything with ease. And to make it last.
Our solution to that is, as an idea, quite simple. We divide communication into two groups - synchronous when we need some data, or we need to do action “right now.” This covers, for example, the aforementioned authorization or getting the accounts list. And asynchronous, where we invert the dependency and expose that some action occurred as an event. The other squad can subscribe to it and react, updating their data. This covers updating the account (which is a reaction in the accounts team) to a new transaction (an event raised by the payments squad).
We also put some more concrete constraints there. For example, the synchronous facade should expose the data as streams (backed by `BehaviorSubject`) so that integration and auto-update (after an event) are easily doable.
Because of that, the data should be automatically provided (when requested), and every failure should be automatically retried. The error should not, in most cases, be visible through a facade because you can’t react to it sensibly - and if you allow reacting to it, you can easily react too much. Multiple teams will show the same error message.
The other kind of interaction, the one where you don’t need data but you need to do something, is even simpler - you expose a properly named & self-contained method that does what you need, the way you need. Making more rules here is really unnecessary.
The other kind of facade, the asynchronous one, is mostly similar, except it does even less. If you do some kind of action, you expose an event that describes what occurred. For example, when the user makes a payment, you expose a data package that tells you what the source and destination accounts was, what the title was, and what amount it covers. Nothing more is exposed. You also don’t store the events - we’re not doing event sourcing or any persistent-event architecture. After all, every event we publish is meant to update some UI or trigger data reload. The heavy lifting is done on the backend.
Navigation
Another form of cross-squad communication is cross-squad navigation. In such a huge domain split between twelve different business squads, navigation to many pages in the applications will be from a different squad.
For example, from the page presenting details of a bank account owned by the accounts squad, there must be a way to navigate to bank transfers owned by the payments squad seamlessly. Such a navigation use case needs to be addressed while adhering to the code ownership principles and code separation between multiple dart packages.
To achieve those objectives, we implemented custom navigation based on the Flutter standard navigation with the following objectives:
- Separation of navigation targets from the page implementation
- Allowing for passing the context data between pages
- Separation of a Navigator from Flutter
Separation from page implementation
To allow for navigation between different squads without exposing the specific page implementation between pages and squads, the page definition has been split between the globally visible target and package-private builder, which builds the page based on data from the target.
The targets are similar to intents known from the Android development world. A target is a class representing a specific page in the app. It can also contain additional context data, which needs to be provided in order to build the page. For example, the target for the bank account details page will contain the bank account number of the account that should be displayed.

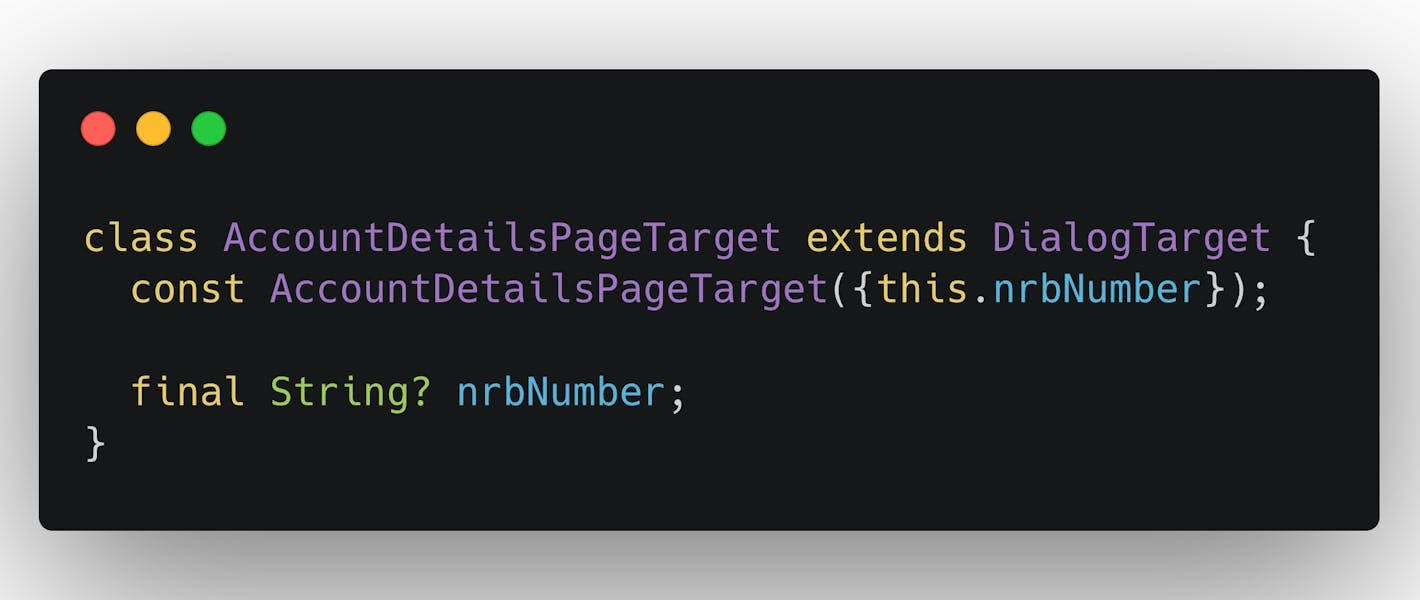
The target is an identifier necessary to execute the navigation; it must be available to all squads that might need to navigate to the page, and thus, the targets are defined in the central navigation package.
Separation from Flutter
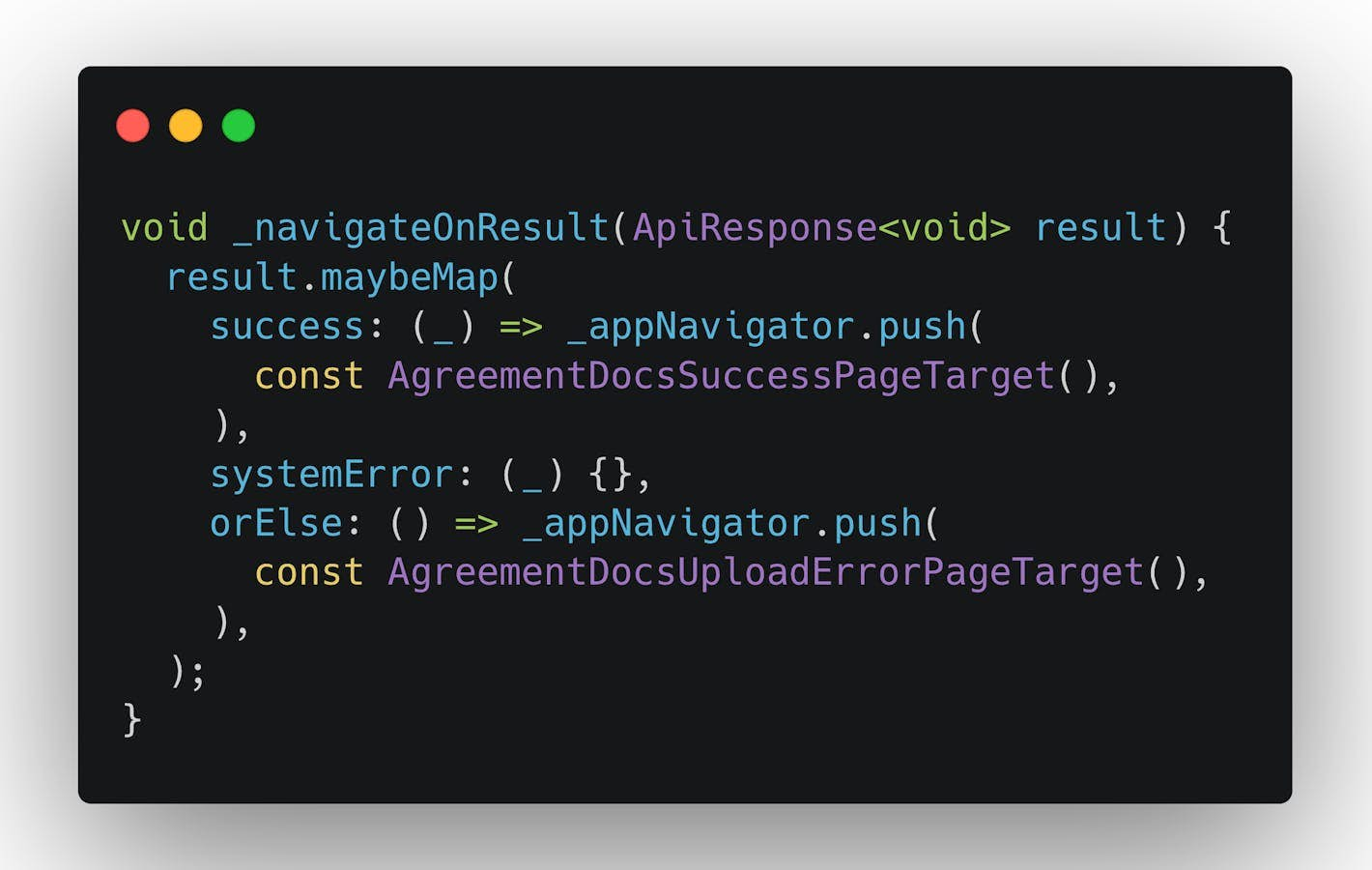
Navigation is a part of business logic, and because of this, it should be available from the bloc/cubit business logic code. However, usually, we avoid introducing a dependency on Flutter in business code. This constraint means we have to trigger the navigation on the view side somehow. This is usually achieved by creating some pseudo-state or by introducing an additional stream for navigation events.
In our solution, because the navigator state is independent of Flutter, we have no issue with passing it to the business logic, and we can execute navigation right from the bloc/cubit.

Localization & Translation Management Systems
The next important thing when developing large Flutter applications is being available to people from different cultures, locales, and countries. Thus, we need a way to set up localization (often put as l10n). Localization “is the process of adapting a product's translation to a specific country or region.”
It’s part of a larger process called internationalization (or i14n). Hundreds of thousands of string values are used across the whole app, and they have to be translated according to the current user locale on their device or personal setting within the app. In our case, there were over 5500 string values that we needed in two languages for the first release, but we also needed the possibility of adding more languages later at a low cost. That’s why you need a localization solution.
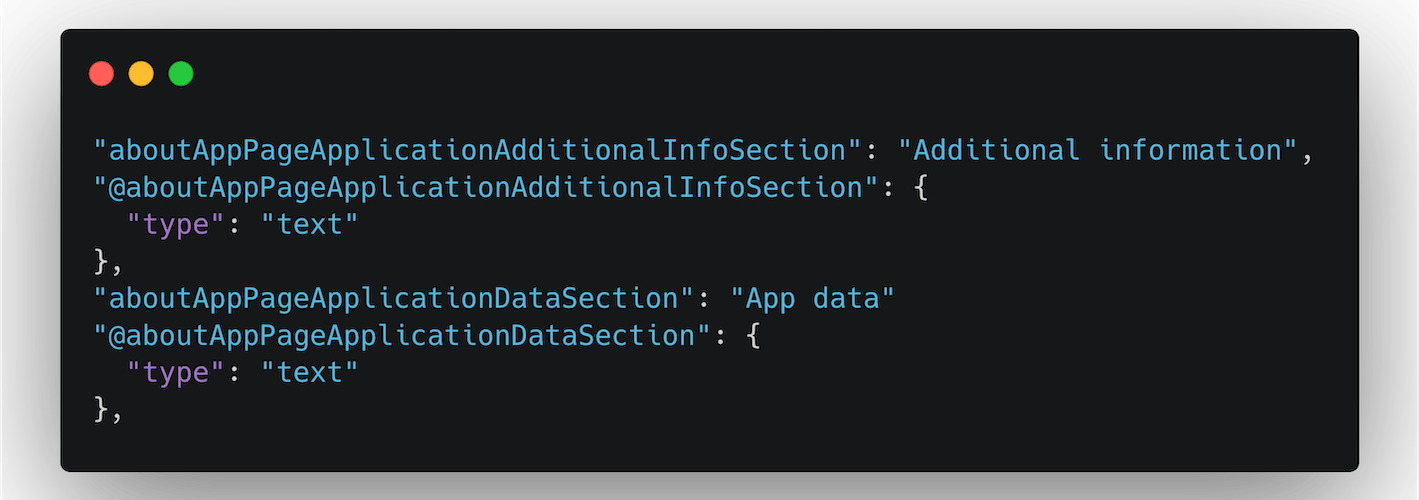
Flutter already has a preferred solution for l10n. There are two main packages from the Flutter team: one called flutter_localizations (for l10n) and another called intl (for i14n). These two are connected, and you can say that they work together to make your app available to everyone. The most popular approach is to use those packages along with .arb format files that contain “key-value” information about each localized string.

The problem is that information about what to localize and how to do it doesn’t come from the development at all. In most cases, it is business knowledge that many people in the organization have processed: marketing people, product owners, translators, and others. Developers are only one small part of that. This gives us a reason to think that localization is no longer a development thing. It’s a product thing. Thus, localization files stored in code repositories should not be a single source of truth for that. Going back to code ownership, localization should also be owned, and that ownership should be transferred to business people.
Fortunately, there already are things for that. They are called Translation Management Systems and typically are web apps optimized for localization workflows. In our project, we used Phrase as a TMS tool because it supports the .arb format and has a lot of convenient features like comments, activity tracking, roles, and advanced translation workflows.
TMS tools can help you with things like:
- Tracking the history of translation terms
- Discuss localization through comments
- Manage a glossary of business domain-related terms that could be uncertain for translators
- Tagging terms
- Importing keys and values from l10n files
- Exporting translations to l10n files
- Versioning translations (like Git in the development world).

Another important thing is to remember that the translation workflow behaves differently than the development process. Thus, we need to have tools that know about it. In a large project, we have business people that make initial localization terms, then it goes to translators (probably more than one) that also send some translations to native speakers to consult and confirm. After that, localizations can be accepted by translators or changed again.
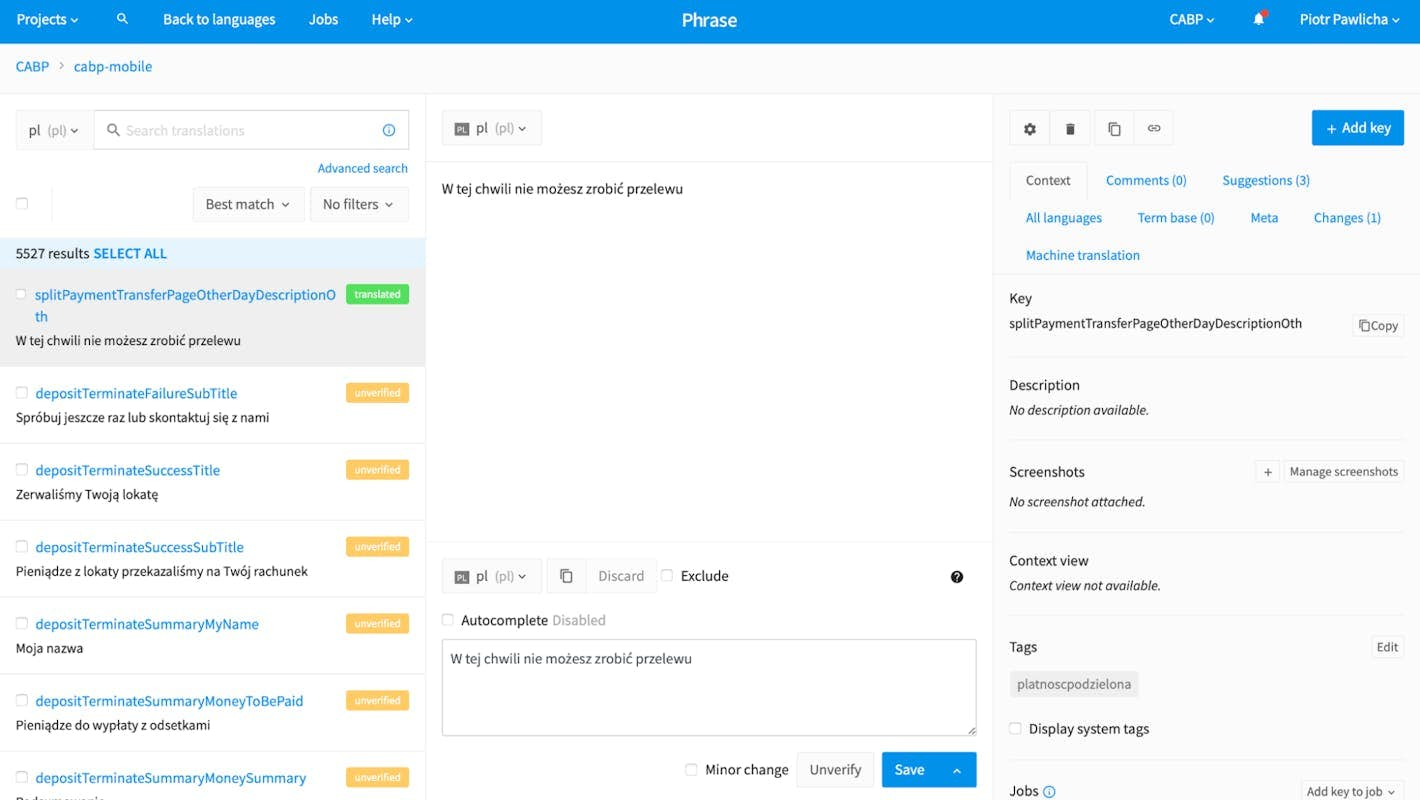
That means we need a way to verify some already translated terms. It’s hard to visualize this process, so let’s take a look at the Phrase workflow diagram:

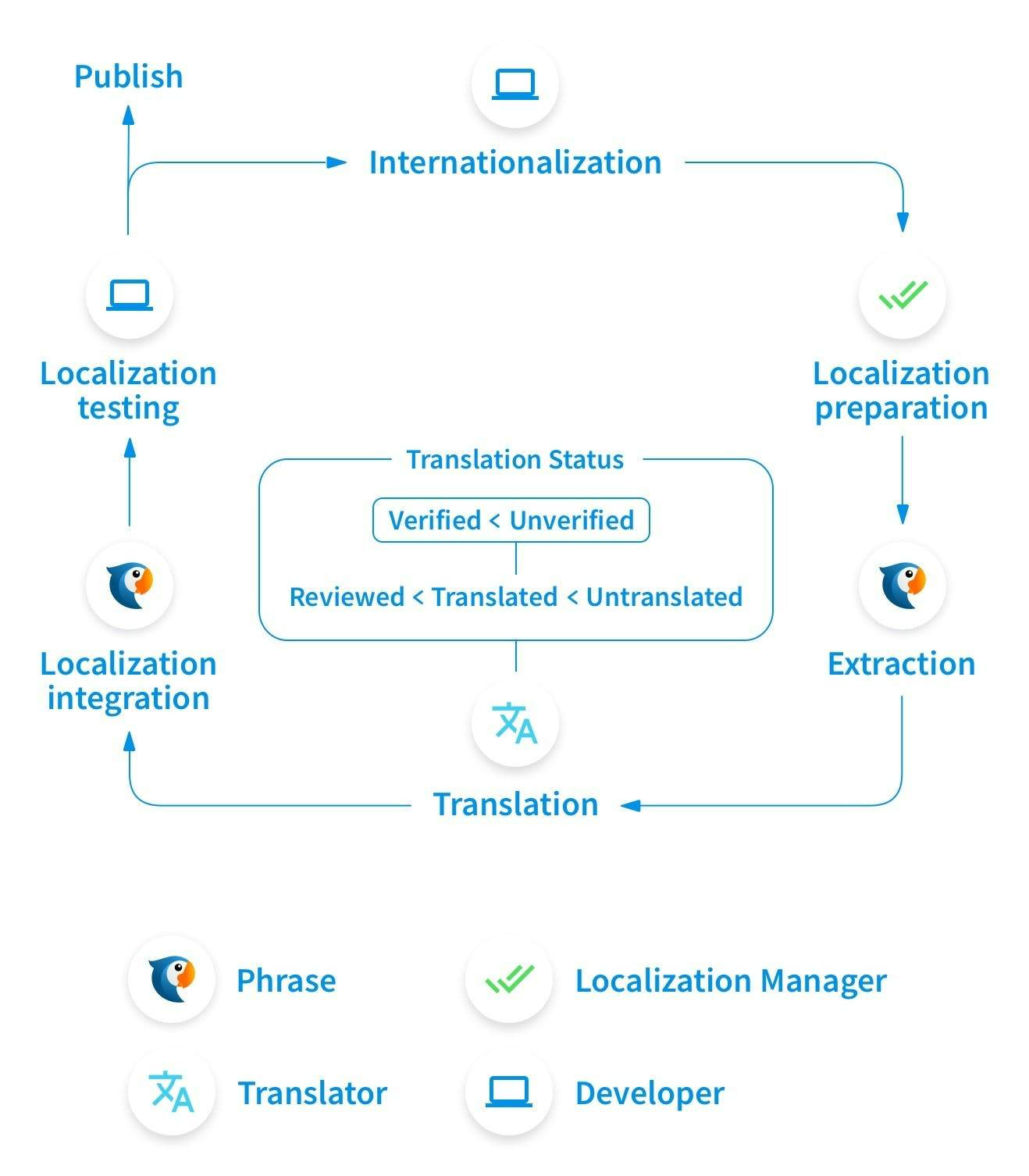
As we can see, it’s a specifically designed workflow for working with localization. TMS tools are crucial to have in your project (even if it’s not large) because using them is simple, and many l10n-specific things are taken care of for us.
Last but not least, check the trial version of your TMS tool first. It’s really important because a lot of TMS tools have different features and handle some specific file formats in different ways, so especially with Flutter .arb files, which are not so popular in the l10n world, you better be sure that the tool you are going to pay for is compatible with your development.
Automatic UI tests
I think we all can agree that UI tests are great. They can simplify testing tremendously. They can lessen the number of regressions. They can give you feedback if you break something right away. They might be hard to maintain, and you probably need to have a dedicated team just for writing UI tests, but it’s still worth it.
Until recently, however, there was a problem with UI Tests and them working within the Flutter app. There were some building blocks like Flutter Driver to test Flutter parts, and you could use Appium for the native parts, but that is cumbersome. It gets even worse if you have two separate teams: one writing the app, the other writing the tests.
Therefore at LeanCode, we have created a totally new approach that will bridge the gap between the native part of the app and the Flutter interface. It is called Patrol, and it is an open-source framework for automated UI testing in Dart for Flutter apps. It helps to handle all kinds of permission dialogs between OS and the Flutter app so that you can easily test the scenario where you need to take the code from an incoming SMS or open push notifications. Patrol is the final building block to make Flutter enterprise-ready.
Having a tool is one thing. Using it properly is a completely different case. When the QA team is separated from the regular development cycle, they work in a cascade mode. Oftentimes writing a good test requires that the QA specialist knows the code. Otherwise, doing the procedure & pinpointing the code owner takes time, although without it you can’t start writing the tests. Eventually, the best person for doing the job will be someone from the inside - a dev. And dev time is precious.
And that creates a problem:
- It takes developers’ time,
- Which, if not accounted for, might be considered “wasted,”
- So it is not in line with PO’s goals,
- Hence they don’t want to do it,
- So developers can’t provide necessary things for people doing UI tests,
- And they waste their time waiting on blockers.
The only solution to that is to make the UI tests a normal part of the SCRUM team. UI tests should probably be a part of the acceptance criteria for each and every user story. Only then will UI tests not cannibalize developer time, and everyone will want to write them - not only devs & testers but also business people. Everyone will have a stake in making them so that they will get created. Since they will be a part of the SCRUM team and will develop simultaneously with features, they will change with them (because most of the time, the changes in the app and in tests would be symmetric), and that will ensure that they will not deteriorate.
In the long run, this is really the only solution if you have a big, multi-team project where different powers pull in different directions.
Also, let’s not forget that UI tests are still tests - and should be treated as tests. You should run them with your normal development workflow. I agree that they might take too long to run, and it might not be feasible to run them on every build, but at least a minimal viable subset should be run that way. And everything else should be run periodically (a couple of times a day at least).
Contracts
We all know that somewhere there is a normal JSON (or XML)-based API. Probably someone will like to call it a REST API, REST-ful, REST-ish, or just “an'' API. Or GraphQL one. That does not really matter. No matter what API style you use, it still requires a non-negligible amount of work.
First and foremost, you must manually manage it. You need to design every endpoint deliberately. You need to consider every aspect of the API: will it be a problem to compose a request? Do I require some other request to be done before this one? Or was a request done after this one? How do we ensure that the same data is passed to a couple of different requests? Or how can we tell that the format of the data will be exactly the same across a single “area” of the API? Although it seems simple, it’s not really that simple: it’s not easy to express that in a structured way.
Yes, we have OpenAPI that allows us to express that, and yes, although manually, we will probably be using some tooling to manage everything. But that won’t be fully automatic. And there will be some OpenAPI-code impedance mismatch. Especially since you will either have both backend and frontend contracts generated out of the OpenAPI schema, and both generators will work slightly differently.
And this mismatch is not the only thing that will cause problems. The clients will work the way the tool wants them to work, which might not make sense to you. You will have to tweak them and then maintain them manually. And if you use some exotic feature or design something just slightly different than the tool authors assumed, your code will break. Sometimes very subtly. And this will push you towards manually writing a client for this single request, and then another, and then another, and you will have a set of manually constructed requests that are unmaintainable, probably broken, or altogether wrong.
Because of these, contract testing is a must - API breakage will be too common to ignore. And finding what broke will be very difficult without a robust set of tests. Or when the backend allows for some ambiguity.
So, our solution to that is “strongly typed contracts.” A concept that is now widely used both in the banking app and at LeanCode.
The idea is simple: since backend devs are the ones that serve the requests, and they have the most “business” knowledge when it comes to how things should move underneath, let them write everything. Both the request schema, the request handlers, and the clients for these requests. But instead of using OpenAPI to design that, let’s use a language that is native to the backend and allows us to express all the things that I was talking about earlier. The backend language is probably some general-purpose one, so parsing it & generating a client that is based on it will probably be a not-so-hard task if we limit the feature set to only the vital things.
This approach has a number of benefits:
- A single source of truth - the backend team dictates how everything looks. Of course, they do so after agreeing with the mobile team on how that needs to look.
- They know the flows, and they know the data they need to manage, so they can preserve the meaning and communicate that to clients using the same language. Plus, a sprinkle of in-code documentation.
- Since they write normal code that is readily usable, they don’t waste time doing documentation (that will, in the end, be thrown away because the requirements change).
- Since everything is code and code that is generated, there isn’t really a place for technical omissions. Basic types are the same everywhere, so if contracts want an `int`, you will not be able to put a `String` there. If everything compiles (both on the backend and client side), there is a very high chance that it is correct.
- Since the client is a normal Dart (/JS) code, the discoverability of it is exactly the same as the rest of the project - you just open “the API” in VSCode or your other favorite editor. You control how the client works, so you can make it readable without sacrificing functionality.
- The contracts are also easily versionable when it comes to schema - you just use git for that and point to a particular commit/tag to use a particular version. Do not confuse this with API versioning. You still need to do that.
What’s best is that it’s Dart all the way, and every mobile developer is/needs to be comfortable with it.
Of course, it’s not a silver bullet.
This does not solve every problem possible and introduces a number of problems on its own. You have a strongly-typed client, so if something changes in the types, you will need to account for that when you update the contracts. And it won’t matter that it changed far away, in a request that you don’t use.
They don’t make the API versioning & supporting easier. You still need to do that, although particular versioning requests are now slightly easier. You can also enforce that the API is backward compatible with proper linting.
And since you operate on high-level types and you have a limited number of types there (because, after all, it is JSON), you can’t really express everything. And everything is typed, so there is less room for ambiguity, and sometimes you need to make things awkward.
Although there are problems, some of them small, some of them amplified, all in all, it is a gigantic net plus that simplifies the development and understanding of the project substantially.
Taming legacy
When we develop a large-scale project, we often make decisions that become outdated over time. Also, those decisions will have to be made in the future, so it’s inevitable. Our code is a legacy from the moment we wrote it. If we wrote it again, there would probably be other things that we’d consider. So it’s okay; we have to accept it. We can’t remove it, but we can tame it. What can we do as developers?
First, we can deprecate things. If some function, widget, class, or even whole module is being used all around the code, but a new way of doing things has to be introduced since business assumptions change, then just deprecate it. In Dart (like other languages), there is an annotation @deprecated that comes in handy for that. It’s really helpful because when there are 20+ developers working on the project, they have to know that this method or class shouldn’t be used and what is the correct way to do that.
However, make sure you really deprecate. The worst thing about deprecation is not obeying it. This introduces even more corruption to our code and communication since both ways of doing one thing are still being used, and new developers don’t know what to choose. Also, we have to remember about broken windows in our code. A broken window in the code means a code smell or something that should obviously be done another way, but there probably was no time for that or any other unpredictable reason. That code will be emerging as more and more corrupted because people wouldn’t bother to refactor things. That’s why we want to make sure about deprecation. Because the objective is to encourage refactoring, we want to minimize concepts that discourage it - such as broken windows.
To ensure policies in our large organization, we have to maintain a technical squad because there must still be an owner to ensure things. The technical squad owns everything that’s not related to any business domain - CI/CD, tooling, cross-squad big picture things and one of those responsibilities is taming legacy. That squad has to organize cycle status events where we can monitor the progress of refactoring deprecated code. That’s why it’s very important to synchronize across squads on a weekly basis or so. We don’t want the inertia to grow silently as we come to the release. If we control it, then it’s not so much of an inertia after all.
Design system
Last but not least is that we should also apply similar constraints when it comes to design. The design of our app basically means UI from the code side, and to make our user experience top-notch, we have to be consistent. What does it mean? It means that good app design should have consistent behaviors, a consistent color palette, consistent approaches to similar user stories and so on, and so on.
Moreover, this should not come from the code because the UX/UI and design don’t come from us - developers. We merely implement the thoughts and concepts of the designers that we work with. That’s why we have to maintain a design system, and we have to do it in tight collaboration with designers.
Developers should always use design system components. The benefits of a design system are maximized when one dedicated squad is responsible for maintaining it. In our organization, it is the Overall Design Squad that is a kind of “master squad” for all designers working on the project. It also has developers that, while continuously interacting with UX/UI people, are developing design system concepts in the codebase.
If you want to learn more about the best practices for building the Design System in Flutter apps, go to our article!
You’ve been warned
The areas we have listed are the tip of the iceberg.
Complex enterprise apps written in Flutter, as in any other framework, require special care from a team of experienced developers. If you want to enhance your own team with that experience, you should consider hiring our Flutter app Developers, who can form hybrid teams with your in-house development team to work on building the next state-of-the-art applications.
If you are looking for a list of enterprise companies that use Flutter for their business apps, we prepared an article you should check out.

Read more

Benefits of a Design System: Why Your Digital Product Needs One
Building a new digital product, such as a web or mobile application, is complex. You need to map user stories - create a simple description of features - then apply them to the developers' scope of work and the app’s design. Discover how a design system can unleash efficiency, consistency, and scalability in your digital product.

Flutter Add to App - Overview and Challenges Based on Real-Life Case
Flutter has taken the mobile market by storm, but not everybody knows that you don’t always have to write a Flutter app from scratch. It can be integrated into your existing application piecemeal. Read more about the Flutter add to app feature.

Banking Apps With Flutter? The Overview and Opinions
The number of banks that have opted for Flutter is growing. Specialists from three banks interviewed - Nubank, ING Silesian Bank, and Credit Agricole Bank Polska - rated Flutter as a 9 (out of 10 point scale). Find out if Flutter really is the right solution for building banking apps.